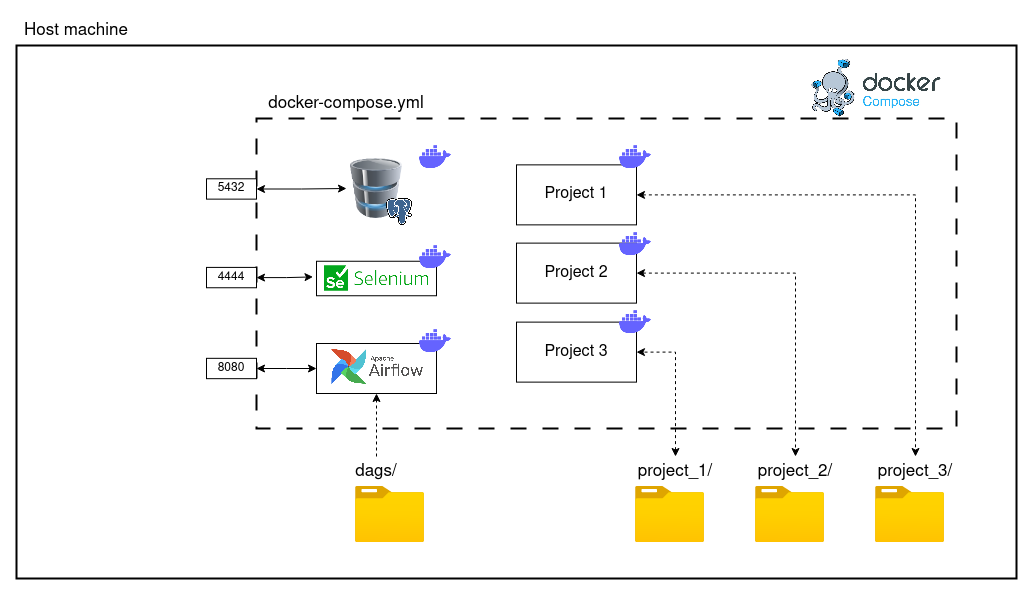
Setting up a webscraping service
As a data engineer is quite common to be on the lookup for useful (or at least interesting) websites to scrape data from. However, it is quite common to have different projects to start the same (e.g. downloading the HTML from the internet) but to end up processing them (ETL) in different ways. Because of this, I have setup a simple Raspberry Pi as my centralized webscraping service where: Websites, files, … can be downloaded into a raw format....