As the amount of personal webscraping projects increased, I realized the importance of having an structured project template. The reason being that it allows to systematically create new projects without having to worry about refactoring later on if it doesn’t match with my webscraping service.
Because of this, I have decided to explain in this post how I structure most of my webscraping projects:
1. Considerations
I like to keep each project as independent from the rest as possible. This allows me to continuously improve each project without worrying about breaking the depending systems. This is why I am a huge fan of employing venvs and containerizing my applications. On top of this I also prefer to keep the scheduling scripts (if any) close to the original repo, as I have seen how keeping everything separated makes the refactoring of existing projects way slower (see 2.2. Scheduling folder for more information).
2. Main structure
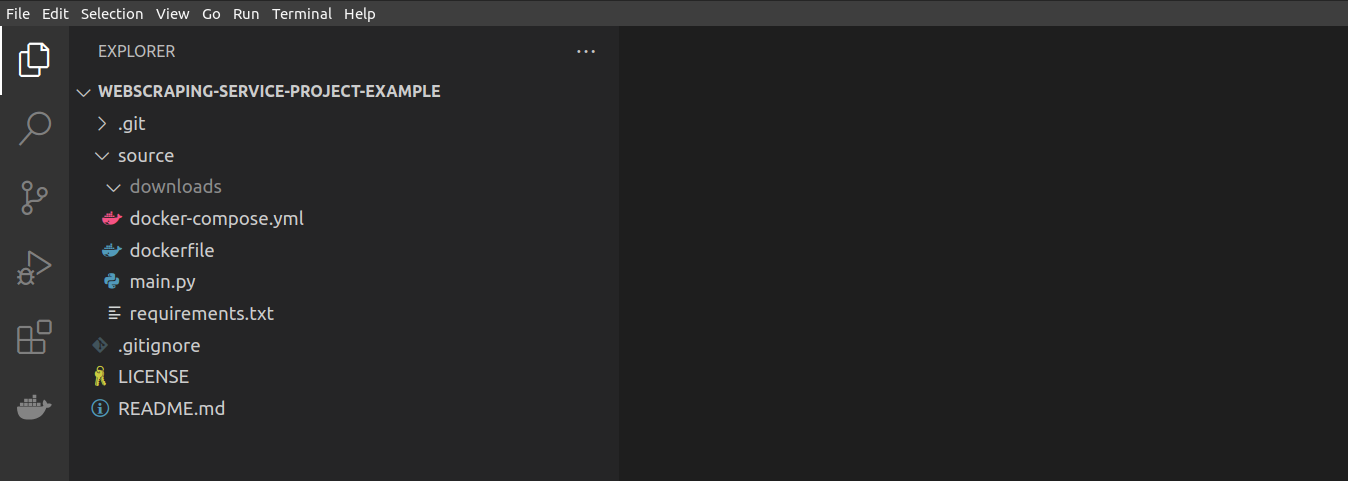
Most of my applications follow the following pattern:
├── .git
├── .gitignore
├── LICENSE
├── README.md
└── source
├── docker-compose.yml
├── dockerfile
├── downloads
├── main.py
├── requirements.txt
└── venv
├── ...
└── ...
2.1. Source folder
This folder contains all the application related logic. This is intentional, as I like separating the actual application code from the repository related code. This has the extra benefit of easing the reusing/copy-pasting of the source code into other projects.
2.2. Scheduling folder
This folder contains all the scheduling related scripts (shell scripts, dags, …). I know this is not a common practice, as I have seen many teams keep their scheduling scripts in a separate repository (if any). Personally, I am not a big fan of this approach as if a migration or refactoring is about to happen (which happens more often that we like to admit), the programmer would need to be aware of how, from where and in which order the application is being run. This easily becomes a bottleneck as the programmer would need to start requesting access to the scheduling tools or start setting meetings with the scheduling team to clarify how everything works before s/he can even begin working!!.
2.3. Downloads folder
This folder is a placeholder for where all the scraped/downloaded files will go. (note that it may contain subfolders depending on the project). However, by keeping it in a separate folder, I can easily replace this location with another one when running the applicatoin as a container (via volumes property of docker). This way I can easily test my projects locally and easily deploy them in docker with minimal code change needed.