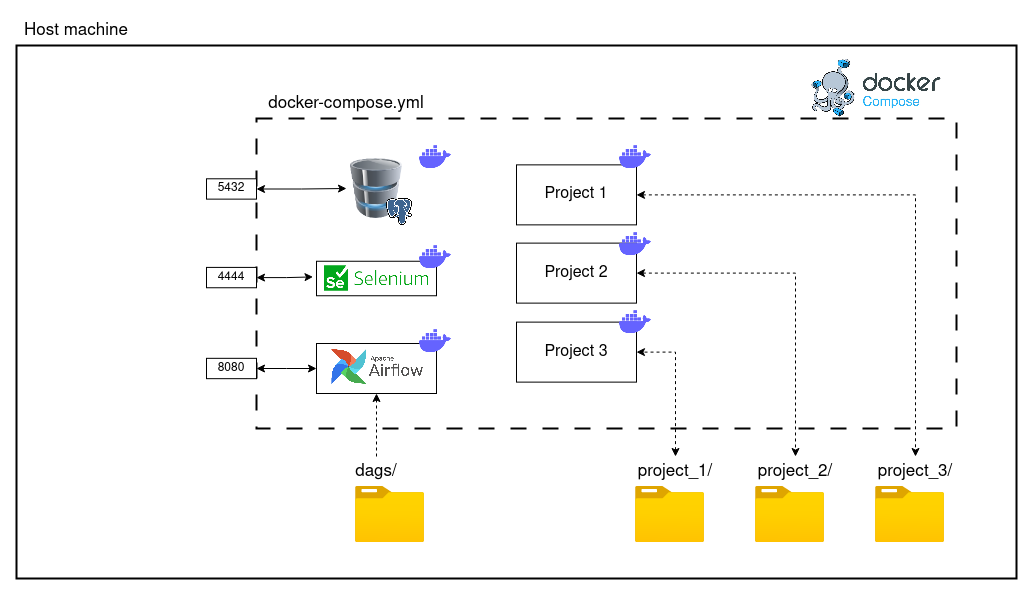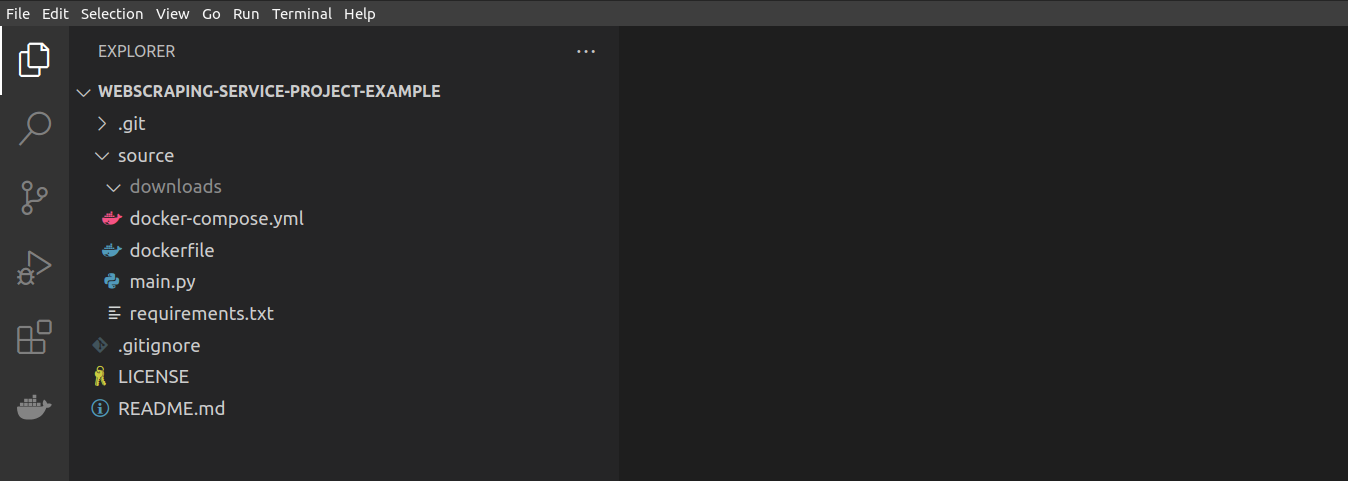
Webscraping project structure
As the amount of personal webscraping projects increased, I realized the importance of having an structured project template. The reason being that it allows to systematically create new projects without having to worry about refactoring later on if it doesn’t match with my webscraping service. Because of this, I have decided to explain in this post how I structure most of my webscraping projects: 1. Considerations I like to keep each project as independent from the rest as possible....